Originally published on Medium.
Speaking into Existence: 3
Chapter 3: From JSONL to SQLite
from r/webdev
Three weeks into using Vociferous daily, the JSONL file was starting to feel like a shoebox full of crumpled receipts. Sure, everything was in there, technically chronological, but finding anything specific meant dumping the entire box onto the table and sifting through it by hand. I’m typically quite comfortable with organized chaos. But this was messy, and it was starting to bother me.
The transition from JSONL to SQLite was my first real architectural migration on this project. It also happened to be where I stumbled into a few design constraints that ended up echoing through every subsequent version I built.
The JSONL Ceiling
Tech Check: What is JSONL?
JSON Lines (JSONL) is a text format where every line is a standalone, valid JSON object. Unlike a standard JSON array that requires enclosing brackets
[]and commas between items, JSONL lets you stream data by simply appending a new line to the bottom of the file. No parsing or rewriting required to add new records.

The original storage model was unapologetically dumb. Every transcription just got dumped into one line in ~/.config/vociferous/history.jsonl:
{"timestamp": "2025-12-14T10:03:22", "text": "Meeting notes about the API redesign...", "duration_ms": 45200}Append-only. Human-readable. Trivially backed up because it’s just a text file. For the first hundred transcripts, this was fine. Honestly, it was perfect. You don’t need a backhoe when a shovel will do.
But by late December, I was hitting the walls hard:
Search was brute-force. Want to find that thought you dictated about API design? Read every line, parse every JSON object, check every text field. With a couple hundred transcripts, my machine didn’t blink. But I was leaning on the tool multiple times a day, and the file was getting heavy.
Updates were catastrophic. When version 1.0.1 dropped, it added editable transcriptions — you could click a box and fix a typo. But editing a line in a JSONL file means rewriting the entire file. Every single typo fix was a full-file rewrite. I was using file locks to pretend I had thread safety, but the whole setup was waiting to shatter.
Organization was impossible. I wanted to group transcripts by project, or at least by purpose. “Focus Groups,” I called them. But a flat text file doesn’t care about relationships. A transcript is just a line, and nothing more.
Rotation was crude, too. When the file hit my arbitrary max limit, the system deleted the oldest entries by — you guessed it — rewriting the entire file minus the top lines. It was a garbage-collection sledgehammer.

Why Not SQLAlchemy from the Start?
💡Tech Check! What is an ORM?
An Object-Relational Mapper (ORM), like SQLAlchemy in Python or Prisma in TypeScript, is a library that lets you interact with a relational database using the object-oriented concepts of your programming language. Instead of writing raw SQL strings (
SELECT * FROM users), you write code (User.query.all()). They are immensely popular for speeding up development, but abstract away how your database actually operates. My general dislike of them has been further fueled by my friend Oswin.
I want to pause here, because this is something I see developers agonizing over constantly: “Should I reach for the ORM immediately?”
My opinion is no. And here’s why, learned the hard way:
When I first booted up the JSONL file, I had no idea what my query patterns were going to be. I didn’t know if I’d need a full-text search index. I didn’t know if I’d need a relational hierarchy. I certainly didn’t know I would eventually need the dual raw/edited text model that ended up defining the project’s identity.

from r/ProgrammerHumor
Living with the JSONL file’s limitations for three weeks forced me to learn exactly what the data layer actually needed to hold up. By the time I sat down to write out the SQLite schema, I wasn’t making guesses in a vacuum — I was just documenting the reality I saw the need for. It worked out well.
The standard advice of “don’t optimize prematurely” gets trotted out as a cliché, but there’s a corollary that’s equally important: don’t abstract prematurely either. An ORM is an abstraction over your data model. If you don’t know your data model yet, I would openly argue using ORMs places you at risk of calcifying your worst premature assumptions.
💡Apt Architecture: The Abstraction Timing Heuristic
I would advise you to wait on introducing an abstraction (like an ORM) until you have felt the pain of the concrete implementation (like raw JSON or SQL). The concrete phase teaches you your actual access patterns. The abstraction phase then optimizes for those known patterns. Abstracting first means optimizing for ghosts and boogeymen you’ve yet to meet.
The Schema That Would Last
💡Tech Check! What is SQLite?
SQLite is a fast, highly reliable, embedded SQL database engine. Most database systems (like PostgreSQL or MySQL) run as massive standalone server processes. SQLite, however, runs directly inside your application and reads/writes to a single, ordinary file on your hard drive, making it the perfect engine for local-first desktop apps like Vociferous!
Version 1.2 landed in early January 2026. My CHANGELOG.md calls it “Major persistence layer overhaul,” which undersells the fact that it was also the moment the project’s data philosophy solidified.
Here’s the schema I designed:
CREATE TABLE transcripts (
id INTEGER PRIMARY KEY AUTOINCREMENT,
timestamp TEXT NOT NULL,
raw_text TEXT NOT NULL,
normalized_text TEXT NOT NULL,
duration_ms INTEGER NOT NULL,
focus_group_id INTEGER REFERENCES focus_groups(id) ON DELETE SET NULL,
created_at TEXT NOT NULL DEFAULT (datetime('now'))
);
CREATE TABLE focus_groups (
id INTEGER PRIMARY KEY AUTOINCREMENT,
name TEXT NOT NULL,
created_at TEXT NOT NULL DEFAULT (datetime('now'))
);
CREATE TABLE schema_version (
version INTEGER NOT NULL
);Three tables. Clean foreign key relationships. But the critical design decision is in the transcripts table: two text columns.
raw_text is what Whisper produced. It’s the machine’s literal output. This column is immutable. No code path in the entire application ever modifies it after creation.
normalized_text is the working copy. This is what the user sees and edits. When the user fixes a typo or rephrases something, normalized_text changes. When the AI grammar refinement engine (which didn’t exist yet, but I was already thinking about it) improves the text, normalized_text changes.
Both fields start with identical values. On creation, raw_text = normalized_text = whatever_whisper_said. Then, they diverge!
Why Immutable Raw Text Matters
I’ve seen enough data systems to know that you never, never destroy the original signal. Here’s why:
- Reproducibility. If the refinement engine mangles something, you can always go back. The original transcription is preserved.
- Quality measurement. If you want to know how much the AI improves transcriptions, you need both the before and after. With only the edited version, you’ve lost the baseline.
- Trust. When the user reads “He was going to the store” in the normalized column, they might wonder what they actually said. Having
raw_textpreserves the ground truth: “him going to the store.” - Debugging. If Whisper starts producing garbage output after a model update, you can audit
raw_textacross transcripts to detect the regression.
This dual-text model was probably the first genuinely prescient architectural decision I made. Not because I’m a genius (I am decisively not), but because I’ve spent enough time untangling broken systems in the field to know exactly what happens when you mutate original data and leave yourself no way to audit the wreckage. You never destroy the ground truth. At least take some pictures before you rip the wiring out!
💡 Apt Architecture: The Principle of Non-Destructive Ingestion
Never mutate the system’s initial ingestion state. Destructive updates to original inputs eliminate your ability to debug future algorithmic regressions, measure feature improvement deltas, or restore user trust. Storage is cheap; lost ground-truth is irreplaceable. Plan accordingly!
The Focus Groups Foundation
The schema included a focus_groups table that I didn’t actually use in v1.2. No UI for it. No API for it. Just the table sitting there, schema’d up and ready.
Why ship a table you’re not using? Because the foreign key relationship (transcripts.focus_group_id REFERENCES focus_groups(id)) informed the ON DELETE SET NULL cascade behavior, and I wanted that constraint in the schema from day one rather than retrofitting it later.
When v1.3 landed a few days later with full Focus Group CRUD operations, the data layer was already done! Adding features was just adding code — no schema changes required. Three cheers for mediocre planning!
This is the value of thinking one step ahead in your data model (and only one step — not five). The schema for v1.2 supported features through v1.4 without modifications because I’d asked the right question: “What’s the next thing I’ll probably need?”
The No-Migration Policy

V1.2 made a ruthless decision: no migration from JSONL.
Users will start with fresh history after upgrade — existing
~/.config/vociferous/history.jsonlis no longer read.
This was the right call, and I’ll explain why, even though it sounds completely user-hostile. Short answer: I still didn’t have any users, so I didn’t really care.
At this point, the product had an installed base of exactly one: me. No support tickets to field. The actual cost of writing a JSONL-to-SQLite migration script from scratch was non-trivial — different fields, different types, and a completely different duration model. The payoff? Preserving a couple weeks of me talking to myself for testing. And I talk to myself often enough, thank-you-very-much.
I didn’t bother. I copied the useful bits manually and moved on. Time spent writing migration logic: zero. Time spent building the actual engine: well spent. That’s exactly how the priority split should look when your total user count fits into one hand. “Sorry, me, myself and I! Your stuff is gone now.”

Years later, when people other than me were actually trusting this tool with real data, migrations became deadly serious. But at v1.2? Scorched earth was the only policy that made sense.
SQLAlchemy: The Experiment
Amusingly, v2.2 would later rewrite the persistence layer again, this time to SQLAlchemy 2.0 ORM. The CHANGELOG calls it an “Architecture Overhaul” and includes this gem:
BREAKING CHANGE: This release resets the local database structure. Legacy history files will be recreated (nuked) upon first launch.
Yes, I nuked my database design again. And nobody could have stopped me! Mwuahahahaha!
Ahem.
Same reasoning: the schema was changing fundamentally, the user count was still one, and writing a migrator for data I could recreate in a day of normal use wasn’t worth the effort.
But the SQLAlchemy experiment is worth mentioning simply because it eventually got ripped back out (lol). By the time v4.0 hit with the web stack migration, I went back to raw SQLite and a rigid migration system. The ORM added a layer of abstraction that just wasn’t pulling its weight — the queries were simple enough that raw, hand-written SQL was clearer and easier to maintain.
It’s a lesson I apparently need to keep relearning the hard way: ORMs are excellent when your queries are dense and your schema is bolted to the floor. They are dead weight when your queries are simple and your schema is still fluid. For Vociferous, it was always going to be simple CRUD and a few aggregations, but the schema needed room to breathe. Raw SQLite with explicit migrations was the right tool for the job. However! That may change slightly very soon; I’m scrutinizing my data analytics features at the moment.
💡 Apt Architecture: The Tool-to-Problem Fit Heuristic
Abstractions like ORMs exist to solve specific operational pain points (e.g., vendor lock-in, complex joint resolutions). If those aren’t your current pain points, the tool introduces friction without yielding Return on Investment. Map tools directly to problems, not to industry defaults! Or fads! Or over-engineering junkies!
The Index Strategy
💡Tech Check! What is a Database Index?
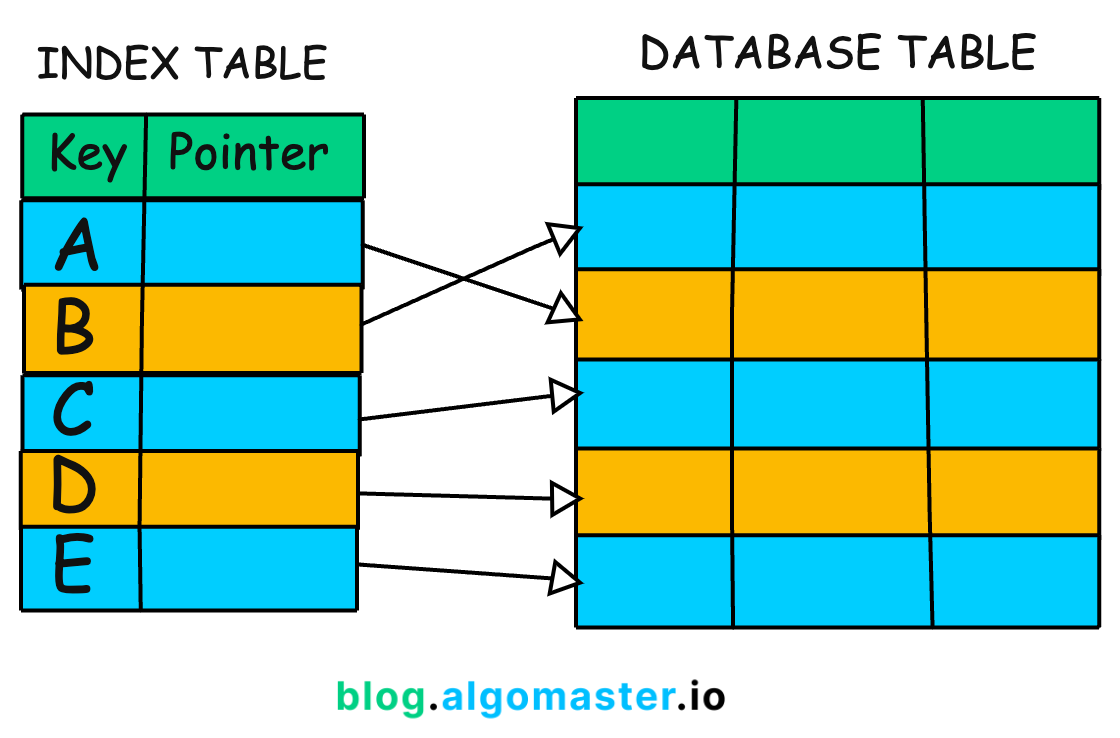
A database index functions much like the index at the back of a large textbook. Instead of the database looking at every single row in a table to find a specific timestamp (a painfully slow “full table scan”), it references a sorted list, pinpoints the row’s physical location on the hard drive, and jumps straight there. Indexes trade a little extra disk space and slightly slower write speeds for massively faster reads.
One thing I got right from the start: indexes. The v1.2 schema included:
- Primary key index on
id(auto-increment, used for ordering) - Index on
timestamp(for date-range queries) - Index on
focus_group_id(for filtered views)
Three indexes, each justifiable by a concrete query pattern. Not “we might need this someday” — “we will run this query on every page load.”
Later, v5.x would add FTS5 (full-text search) indexing, WAL mode for concurrent read/write, and more sophisticated index strategies. But the v1.2 foundation was solid because it was minimal and intentional.
What Data Architecture Teaches You
The JSONL-to-SQLite migration was a practical way to beat a specific reality into my head regarding data models:
Your data model is your product’s memory. It is the exact boundary of what the system is capable of remembering, how it structures that memory, and what questions it is allowed to answer about its own past. Get the foundation completely wrong, and no amount of clever UI polish will save you. The tool will just feel dumb and forgetful.
The dual-text model wasn’t just a technical lever to pull, it was a product constraint demanding some respect. It planted its feet and said: “This tool respects what you actually said. It will never pretend an AI wrote your thoughts. The ground truth stays.” A dozen versions later, through Focus Groups, duration tracking, variant engines, and full-text indexing, that original raw_text column has never been touched. It is exactly what it was when I wrote the v1.2 schema in a messy room late at night: the immutable truth of what the machine actually heard.
Now, let’s be honest. There’s enough AI writing on the web today. Replacing what you wrote without your consent, even if it was originally your voice, is wrong. Vociferous is not an AI slop generator, and I’ll never let it become one.

Vociferous is an open-source, offline speech-to-text application. It runs entirely on your hardware, no cloud required. Both CPU and GPU are supported.